Introduction
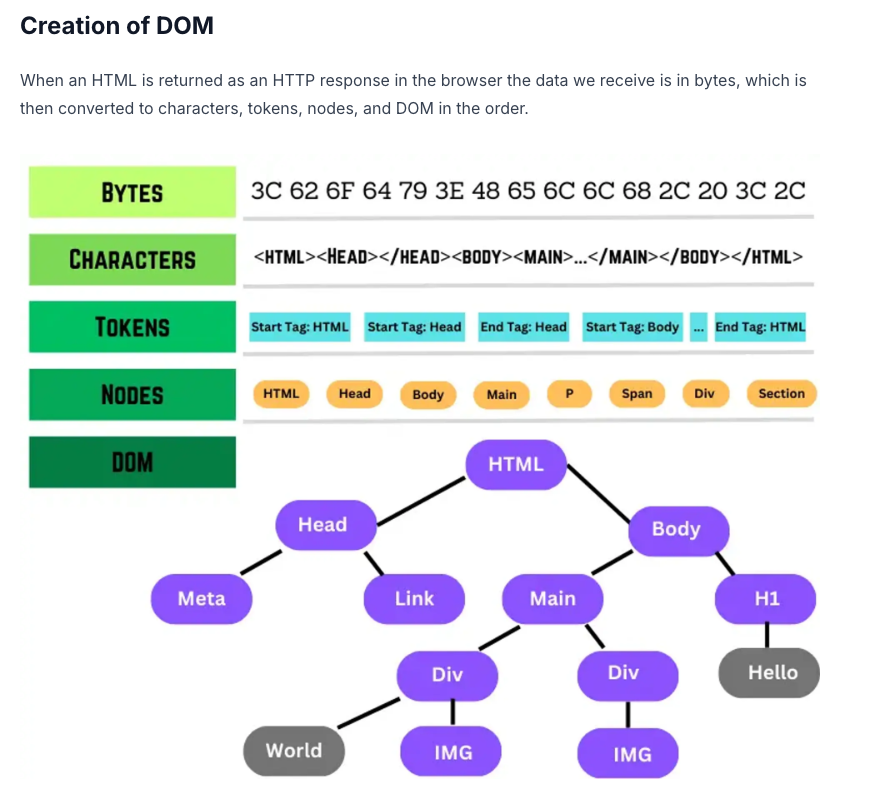
Browsers parse HTML to create the DOM, enabling web pages to be rendered. In this blog, we’ll build a simple JavaScript script that mimics this process.
How DOM Parsing Works
- Tokenization – Identifies HTML elements like
<html>,<p>, etc. - Tree Construction – Creates a hierarchical structure.
- Text Processing – Extracts text inside elements.
Our parser will follow these steps.
Building a Simple HTML Parser
Here’s the first iteration of code that I wrote, the code is not optimised it uses deep recursion & an array of tokens instead of Set.
const htmlCharacters = '<html><head></head><body><main><h1>Hello, this is H1</h1><p>I am a para tag</p></main><section><p>This is a section</p></section></body></html>';
const tokens = ['html','head','body','main','h1','p','section']
const dom = {};
const getToken = (str) => {
let token = '';
for(let i = 0; i < str.length; i++) {
const curr = str[i];
if(curr === '>' || curr === '/') {
break;
}
if(curr === '<') {
continue;
}
token += curr;
}
if(tokens.includes(token)) {
return {token, isChildren: false};
}
return {token, isChildren: true};
}
const contructDom = ({
characters, dom
}) => {
if(characters.length <= 0) {
return {
dom: null,
nextIndex: -1,
nextCharacters: ''
}
}
const foundToken = getToken(characters);
let nextIndex = characters.indexOf('>') + 1;
let nextCharacters = characters.slice(nextIndex);
let {token, isChildren} = foundToken;
if(!token) {
return {
dom: null,
nextIndex,
nextCharacters
}
}
if(isChildren) {
console.log({
isChildren,
token,
nextIndex,
nextCharacters
})
return {
isChildren,
token,
nextIndex,
nextCharacters
}
}
while(nextIndex > -1) {
const constructedDOM = contructDom({
characters: nextCharacters,
dom: {}
});
if(!dom[token]) {
dom[token] = {}
}
const currDomToken = {}
if(constructedDOM.isChildren) {
dom[token] = {textContent: constructedDOM.token};
} else {
dom[token] = {...dom[token], ...constructedDOM.dom};
}
nextIndex = constructedDOM.nextIndex;
nextCharacters = constructedDOM.nextCharacters;
characters = nextCharacters;
}
return {dom, nextIndex, nextCharacters};
}
const constructedDOM = contructDom({
characters: htmlCharacters,
dom
});
console.log(JSON.stringify(constructedDOM.dom))
Here’s more optimised version of the code, it uses stack to avoid deep recursion & uses Set which helps in faster lookups.
const html = '<html><body><h1>Hello</h1><p>Paragraph</p></body></html>';
const tokens = new Set(['html', 'body', 'h1', 'p']);
const parseToken = (str) => str.match(/^<([^\/>]+)>/)?.[1];
const constructDOM = (html) => {
let index = 0, stack = [], root = {}, current = root;
while (index < html.length) {
const token = parseToken(html.slice(index));
if (token) {
index = html.indexOf('>', index) + 1;
if (tokens.has(token)) {
let node = { tag: token, children: [] };
current.children = current.children || [];
current.children.push(node);
stack.push(current);
current = node;
}
} else if (html[index] === '<' && html[index + 1] === '/') {
index = html.indexOf('>', index) + 1;
current = stack.pop();
} else {
let textEnd = html.indexOf('<', index) || html.length;
let text = html.slice(index, textEnd).trim();
if (text) current.textContent = text;
index = textEnd;
}
}
return root;
};
console.log(JSON.stringify(constructDOM(html), null, 2));
Conclusion
This simple parser mimics how browsers process HTML. Try modifying & experimenting it to handle attributes and more complex structures!
Happy coding!